
Aprendiendo R: Estadística Aplicada y Métodos Cuantitativos
Published:
El curso se desarrolló completamente en modalidad online y estuvo estructurado en dos grandes etapas: una primera instancia más introductoria y liviana, y una segunda etapa considerablemente más profunda en términos metodológicos. El trabajo previo fue clave: antes de cada clase se nos compartían cápsulas en video y materiales que debían ser revisados con antelación para asegurar un correcto desarrollo de las sesiones sincrónicas.
El curso comenzó con la instalación y configuración de R y RStudio, junto con una introducción al entorno de trabajo y a los principios básicos del análisis estadístico en R. A partir de distintas bases de datos real, se abordaron pruebas t y análisis de varianza (ANOVA), aprendiendo a formular contrastes, evaluar supuestos y extraer conclusiones sobre diferencias de medias, varianzas y relaciones entre variables.
Posteriormente se trabajó con técnicas de regresión y correlación, profundizando tanto en la interpretación estadística como en la correcta presentación gráfica de los resultados. Esta etapa puso especial énfasis en la visualización como herramienta central para comunicar resultados cuantitativos de manera clara y rigurosa.
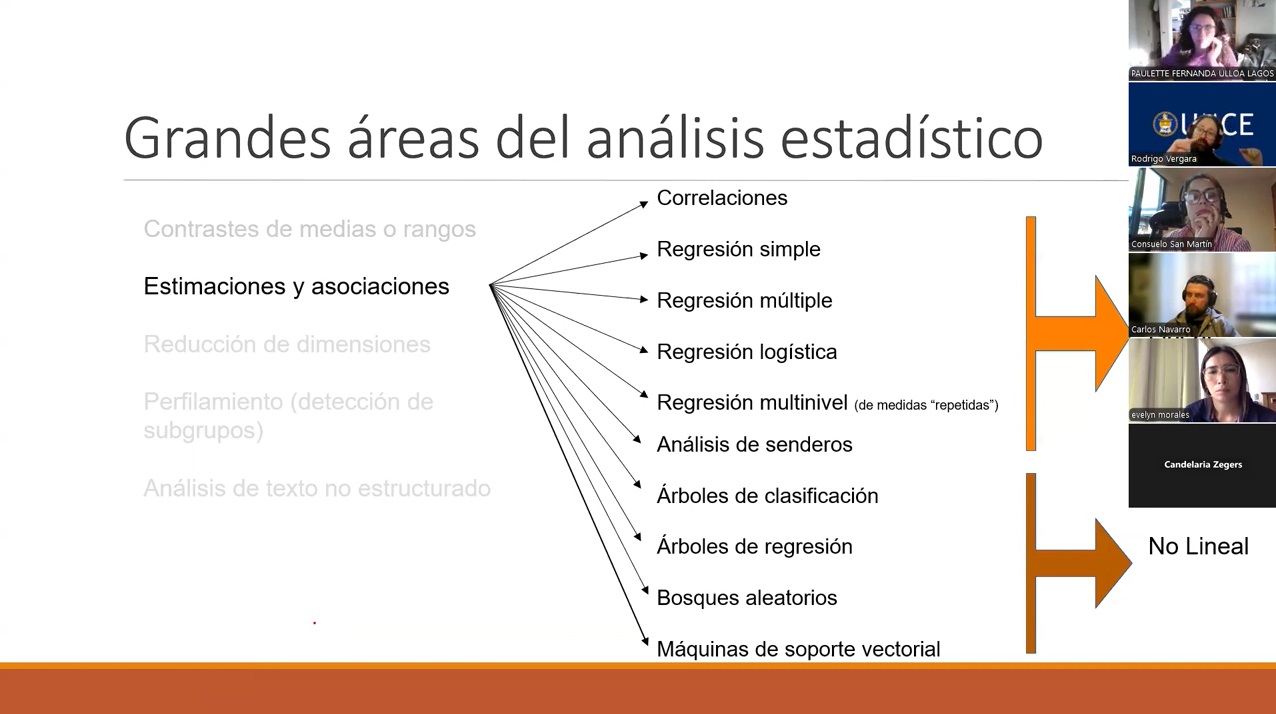
Figura 1: Una de las clases.
La segunda etapa del curso correspondió a una introducción a la metodología cuantitativa avanzada, donde se revisaron las grandes áreas del análisis estadístico y su relación entre sí. Se abordaron contrastes de medias y rangos, estimaciones y asociaciones mediante correlaciones y distintos tipos de regresión (simple, múltiple, logística y multinivel).
Además, se introdujeron métodos no lineales y de aprendizaje automático, incluyendo árboles de clasificación y regresión, bosques aleatorios y máquinas de soporte vectorial. Estas técnicas fueron presentadas como extensiones naturales del enfoque estadístico clásico, más que como herramientas aisladas.
El curso también abordó técnicas de reducción de dimensiones, como el análisis de componentes principales (PCA), el análisis factorial y métodos no lineales, así como estrategias de perfilamiento y detección de subgrupos mediante análisis de conglomerados jerárquicos, k-medias y clases latentes. Finalmente, se introdujeron nociones de análisis de texto no estructurado y procesamiento de lenguaje natural.
Esta segunda etapa permitió integrar los distintos enfoques en un flujo de análisis combinado, orientado a detectar patrones, reducir la complejidad de los datos y construir modelos predictivos. Más que profundizar en la implementación técnica de cada método, el énfasis estuvo en comprender cuándo y por qué utilizar cada estrategia dentro de un marco metodológico coherente.
Si bien gran parte de los contenidos ya me resultaban familiares por mi formación doctoral, el principal valor del curso estuvo en revisarlos desde una nueva perspectiva: más aplicada, más orientada al uso cotidiano de R y con ejemplos cercanos a contextos biológicos. Fue una buena oportunidad para ordenar conocimientos, actualizar prácticas y reforzar el uso de R como lenguaje común para el análisis estadístico aplicado.
Finalmente, quiero agradecer a Rodrigo Vergara, profesor del curso, quien amablemente nos invitó a participar como oyentes y a ser parte de esta instancia formativa. Su estilo de enseñanza, cercano y de lenguaje coloquial, facilita enormemente la comprensión de contenidos que muchas veces pueden resultar lejanos o abstractos, logrando que herramientas y conceptos estadísticos complejos se vuelvan accesibles y aplicables en contextos reales.